
《知识图谱:方法、实践与应用》阅读笔记(2)知识图谱的存储
第三章 知识图谱的存储
引言:
一方面,以文件形式保存的知识图谱显然无法满足用户的查询、检索、推理、分析及各种应用需求;另一方面,传统数据库的关系模型与知识图谱的图模型之间存在显著差异,关系数据库无法有效地管理大规模知识图谱数据。
为了更好地进行三元组数据的存储,语义万维网领域发展出专门存储RDF 数据的三元组库;数据库领域发展出用于管理属性图的图数据库。
3.1 知识图谱数据库基本知识
两种主要图数据模型:RDF 图和属性图
3.1.1 知识图谱数据模型
知识图谱数据模型的数学基础源于有着近 300年历史的数学分支——图论。
1. RDF图
RDF 是 W3C 制定的在语义万维网上表示和交换机器可理解信息的标准数据模型。在 RDF 三元组集合中,每个 Web 资源具有一个 HTTP URI 作为其唯一的 id。
HTTP URI(Uniform Resource Identifier)是一种用于标识Web资源的标准化字符串。URI是一种通用的资源标识方案,其中HTTP URI是基于HTTP协议的特定类型。它有两种主要的格式:
URL(Uniform Resource Locator):
常见的Web地址,表示资源的位置。
- 示例:
http://example.com/page表示某个网站上的页面。URN(Uniform Resource Name): 仅用于标识资源的名称,但不指示具体的访问方式或位置(在实践中较少使用)。
一个 RDF 图定义为三元组 (s, p, o) 的有限集合;每个三元组代表一个陈述句,其中 s 是主语,p 是谓语,o 是宾语;(s, p, o) 表示资源 s 与资源 o 之间具有联系 p,或表示资源 s 具有属性 p 且其取值为 o。实际上,RDF 三元组集合即为图中的有向边集合。
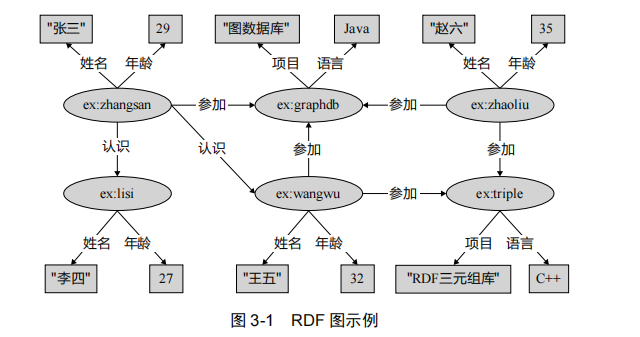
值得注意的是,RDF 图对于节点和边上的属性没有内置的支持。
节点属性可用三元组表示,这类三元组的宾语称为字面量,即图中的矩形。例如,(ex: zhangsan, 姓名, “张三”)。
边上的属性常利用一种叫做 **“具体化”(reification)**的技术,额外引入关系节点表示整个三元组,将边属性表示为以该节点为主语的三元组。
例如在图 3-2 中,引入节点ex:participate 代表三元组 (ex:zhangsan, 参加, ex:graphdb) ,该节点通过 RDF 内置属性 rdf:subject、rdf:predicate 和 rdf:object 分别与代表的三元组的主语、谓语和宾语建立起联系,这样三元组(ex:participate, 权重, 0.4)就实现了为原三元组增加边属性的效果。
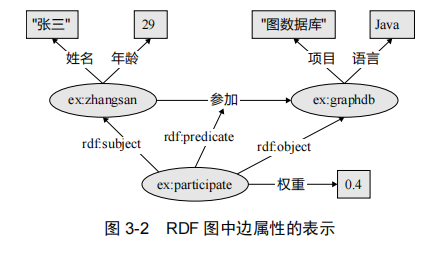
2. 属性图
个人理解:所有节点都是一个map的有向图
属性图可以说是目前被图数据库业界采纳最广的一种图数据模型。属性图由节点集和边集组成,且满足如下性质:
(1)每个节点具有唯一的 id;
(2)每个节点具有若干条出边;
(3)每个节点具有若干条入边;
(4)每个节点具有一组属性,每个属性是一个键值对;
(5)每条边具有唯一的 id;
(6)每条边具有一个头节点;
(7)每条边具有一个尾节点;
(8)每条边具有一个标签,表示联系;
(9)每条边具有一组属性,每个属性是一个键值对。
3.1.2 知识图谱查询语言
目前,RDF 图上的查询语言是 SPARQL;
属性图上的查询语言常用的是 Cypher 和 Gremlin。
1. SPARQL
举个栗子:
(1)查询程序员张三认识的其他程序员
1 | PREFIX ex: <http://www.example.com/> |
输出:
1 | ex:lisi |
说明:PREFIX 关键字将 ex 定义为 URI http://www.example.com/ 的前缀缩写,WHERE 关键字指明了查询的三元组模式(Triple Pattern),SELECT 关键字列出了要返回的结果变量。三元组模式查询是最基本的 SPARQL 查询。
2.Cypher
Cypher 最初是图数据库 Neo4j 中实现的属性图数据查询语言。
与 SPARQL 一样,Cypher 也是一种声明式语言,即用户只需要声明“查什么”,而无须关心“怎么查”。(和SQL一样)
举个栗子:
(1)查询图中的所有程序员节点
1 | MATCH (p:程序员) |
输出:
1 | {姓名=张三, 年龄=29} |
(2)查询程序员与“图数据库”项目之间的边
1 | MATCH (:程序员)-[r]->(:项目{name:'图数据库'}) |
输出:
1 | (1)-[参加{权重=0.4}]->(3) |
3.Gremlin
Gremlin 是 Apache TinkerPop 图计算框架提供的属性图查询语言。
Gremlin 的定位是图遍历语言,其执行机制好比是一个人置身于图中沿着有向边,从一个节点到另一个节点进行导航式的游走。
这类语言的优点是可以时刻知道自己在图中所处的位置,以及是如何到达该位置的;缺点是用户需要“认识路”!
与受到SQL 影响的声明式语言 SPARQL 和 Cypher 不同,Gremlin 更像一种函数式的编程语言接口。
举个栗子:
(1)列出图中所有节点的属性
1 | g.V |
输出:
1 | {姓名=张三, 年龄=29} |
说明:V 表示节点集合。
(2)列出图中所有的边
1 | g.E |
输出:
1 | e[7][1-认识->2] |
说明:E 表示边集合。
(3)查询从节点 1 出发的标签为“认识”的边
1 | g.v(1).outE('认识') |
输出:
1 | e[7][1-认识->2] |
说明:v(1)选取 id 为 1 的节点;outE 表示节点的出边集合,outE(‘认识’)是标签为“认识”的出边集合。
3.2 常见知识图谱存储方式
本节介绍三类知识图谱数据库:
-
基于关系数据库的存储方案
-
面向 RDF 的三元组数据库
-
原生图数据库
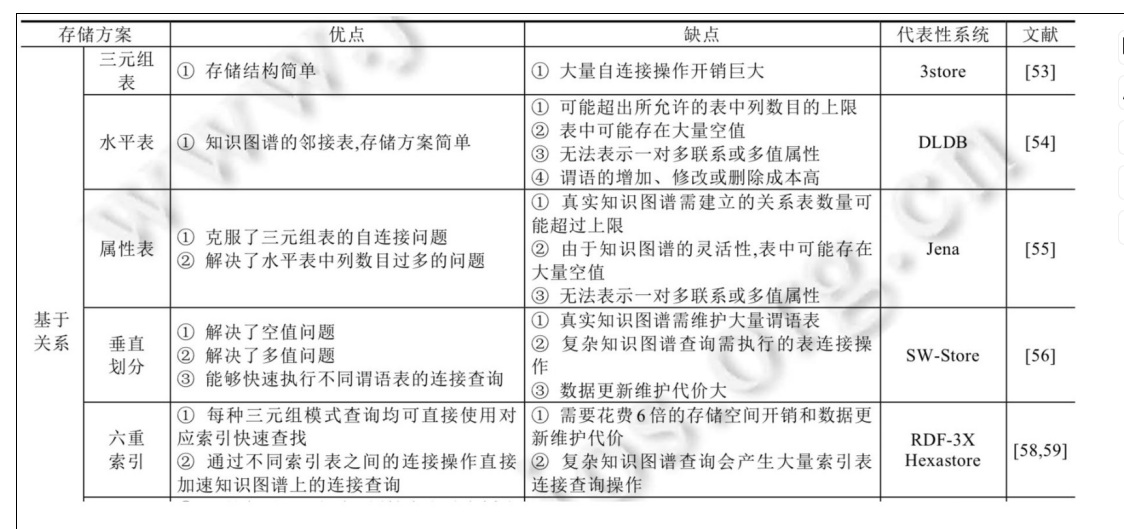
3.2.1 基于关系数据库的存储方案
1.三元组表
三元组表是将知识图谱存储到关系数据库的最简单、最直接的办法,就是在关系数据库中建立一张具有 3 列的表,该表的模式为
三元组表 (主语, 谓语, 宾语)

三元组表存储方案虽然简单明了,但三元组表的行数与知识图谱的边数一样,其最大问题在于将知识图谱查询翻译为 SQL 查询后的三元组表自连接。
查找 1850 年出生且 1934 年逝世的创办了某公司的人:
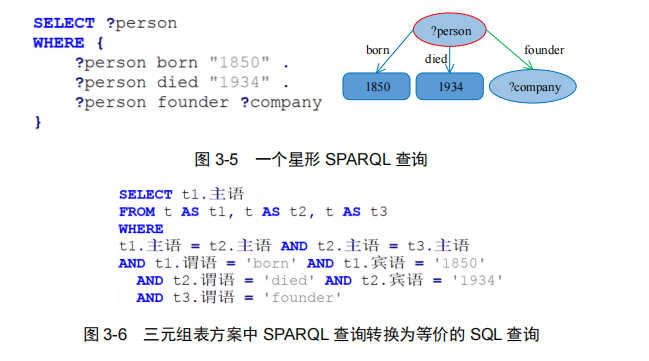
2.水平表
水平表每行记录存储一个知识图谱中一个主语的所有谓语和宾语。
实际上,水平表就相当于知识图谱的邻接表。
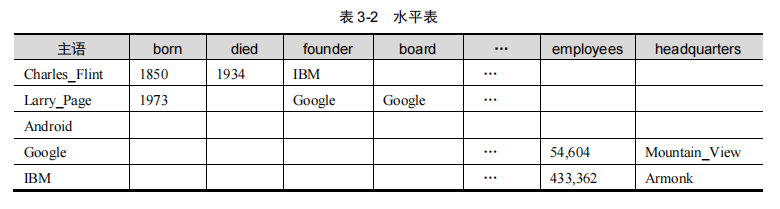
优点:

缺点:存在大量空值,浪费空间。
但是水平表的缺点在于:所需列的数目等于知识图谱中不同谓语数量,在真实知识图谱数据集中,不同谓语数量可能为几千个到上万个,很可能超出关系数据库允许的表中列数目的上限;对于一行来说,仅在极少数列上具有值,表中存在大量空值。
3.属性表
属性表(Property Table)存储方案是对水平表的细化,将同类主语分到一个表中,不同类主语分到不同表中。这样就解决了表中列的数目过多的问题。
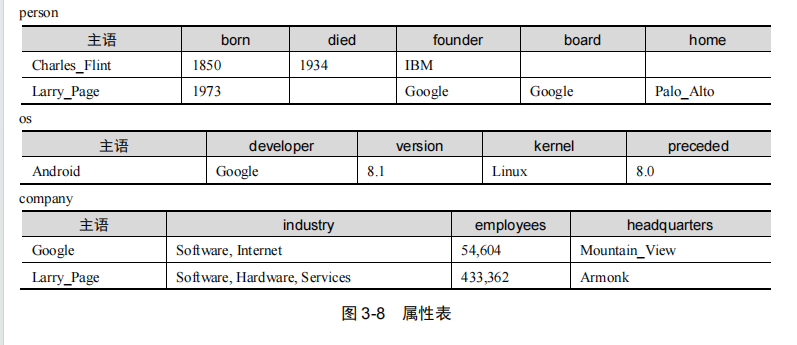

属性表既克服了三元组表的自连接问题,又解决了水平表中列数目过多的问题。
但属性表方案仍有缺点:
- 对于规模稍大的真实知识图谱数据,主语的类别可能有几千个到上万个,按照属性表方案,需要建立几千个到上万个表,这往往超过了关系数据库的限制。
- 对于知识图谱上稍复杂的查询,属性表方案仍然会进行多个表之间的连接操作,从而影响查询效率。
- 即使在同一类型中,不同主语具有的谓语集合也可能存在较大差异,这样会造成与水平表中类似的空值问题。
采用属性表存储方案的代表是 RDF 三元组库 Jena。
4.垂直划分
垂直划分(Vertical Partitioning)存储方案是由美国麻省理工学院的 Abadi 等人在 2007 年提出的 RDF 数据存储方法。
该方法以三元组的谓语作为划分维度,将 RDF 知识图谱划分为若干张只包含(主语, 宾语)两列的表,表的总数量即知识图谱中不同谓语的数量;也就是说,为每种谓语建立一张表,表中存放知识图谱中由该谓语连接的主语和宾语值。

每个谓语表都按主语列的值进行排序,能够使用归并排序连接(Merge-sort Join)快速执行不同谓语表的连接查询操作。
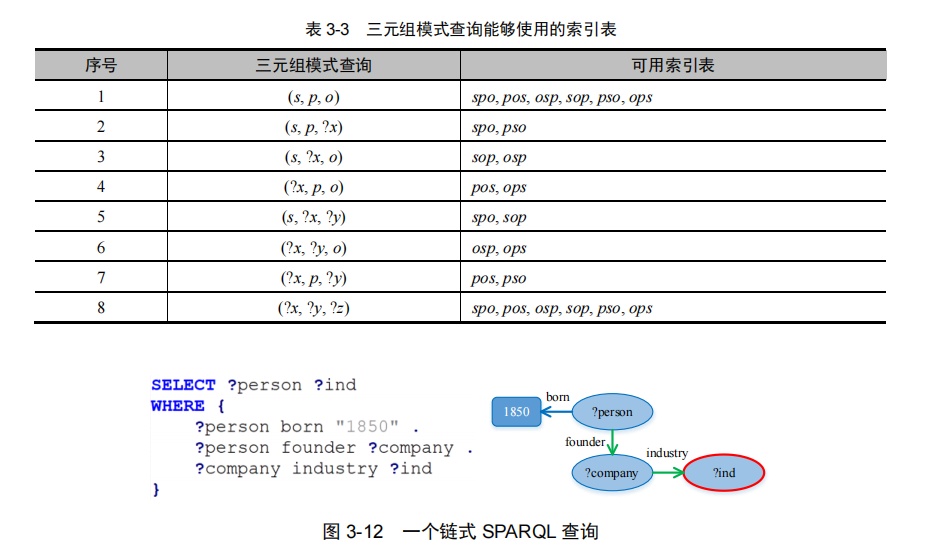
5.六重索引
六重索引(Sextuple Indexing)存储方案是对三元组表的扩展,是一种典型的“空间换时间”策略,其将三元组全部 6 种排列对应地建立为 6 张表。
六重索引存储方案存在的问题包括:虽然部分缓解了三元组表的单表自连接问题,但需要花费 6 倍的存储空间开销、索引维护代价和数据更新时的一致性维护代价。
6.DB2RDF
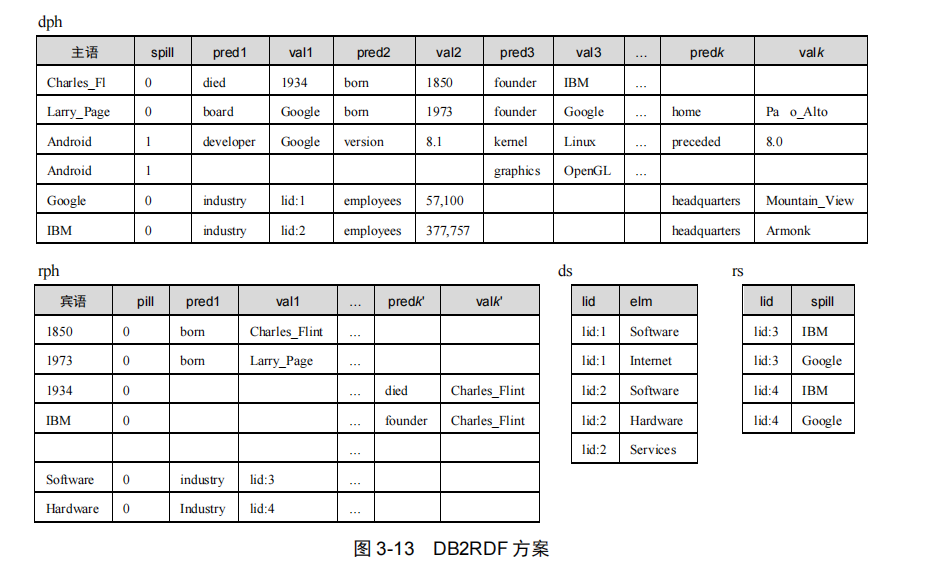
DB2RDF 是由 IBM 研究中心于 2013 年提出的一种面向实体的 RDF 知识图谱存储方案,该方案是以往 RDF 关系存储方案的一种权衡折中,既具备了三元组表、属性表和垂直划分方案的部分优点,又克服了这些方案的部分缺点。
三元组表的优势在于“行维度”上的灵活性,即存储模式不会随行的增加而变化;DB2RDF 方案将这种灵活性扩展到“列维度”上,即将表的列作为谓语和宾语的存储位置,而不将列与谓语进行绑定。
DB2RDF 存储方案由 4 张表组成,即 dph 表、rph 表、ds 表和 rs 表;图 3-13 给出了 图 3-4 中知识图谱对应的 DB2RDF 存储方案。
-
**dph(direct primary hash)**是存储方案的主表,该表中一行存储一个主语(主语列)及其全部谓语(predi 列)和宾语(vali 列)。
-
对于多值谓语的处理,引入 ds(direct secondary hash)表。当 dph 表中遇到一个多值谓语时,则在相应的宾语处生成一个唯一的 id 值;将该 id 值和每个对应的宾语存储为 ds表的一行。例如,在图 3-13 的 dph 表中,主语 Google 的谓语 industry(pred1 列)是多值谓语,则在其宾语列(val1)存储 id 值 lid:1;在 ds 表中存储 lid:1 关联的两个宾语Software 和 Internet。
-
为了提高查询处理效率,还需要存储实体节点的入边信息(从宾
语经谓语到主语)。为此,DB2RDF 方案提供了 rph(reverse primary hash)表和 rs(reverse secondary hash)表。

小结

![[书生大模型]论文分类微调打榜赛二等奖-比赛方案分享](https://picbed.octalzhihao.top/img/myblog/cover/default_cover_15.webp)
![[Datawhale AI夏令营] 语音克隆比赛方案](https://picbed.octalzhihao.top/img/myblog/cover/default_cover_5.webp)

