
《知识图谱:方法、实践与应用》阅读笔记(1)知识图谱表示与建模
第二章 知识图谱表示与建模
知识图谱表示(Knowledge Graph Representation)指的是用什么语言对知识图谱进行建模,从而可以方便知识计算。从图的角度来看,知识图谱是一个语义网络,即一种用互联的节点和弧表示知识的一个结构。
2.1 什么是知识表示
无论是语义网络,还是框架语言和产生式规则,都缺少严格的语义理论模型和形式化的语义定义。为了解决这一问题,人们开始研究具有较好的理论模型基础和算法复杂度的知识表示框架。比较有代表性的是描述逻辑语言(Description Logic)。描述逻辑是目前大多数本体语言(如 OWL)的理论基础。
语义网的基础数据模型 RDF 受到了元数据模型、框架系统和面向对象语言等多方面的影响,其最初是为人们在 Web 上发布结构化数据提供一个标准的数据描述框架。
与此同时,语义网进一步吸收描述逻辑的研究成果,发展出了用 OWL 系列标准化本体语言。
随着表示学习的发展,以及自然语言处理领域词向量等嵌入(Embedding)技术手段的出现,启发了人们用类似于词向量的低维稠密向量的方式表示知识。通过嵌入将知识图谱中的实体和关系投射到一个低维的连续向量空间,可以为每一个实体和关系学习出一个低维度的向量表示。

2.2 人工智能早期的知识表示方法
2.2.1 一阶谓词逻辑
一阶谓词逻辑(或简称一阶逻辑)(First Order Logic)是公理系统的标准形式逻辑。

2.2.2 霍恩子句和霍恩逻辑
霍恩子句(Horn Clause)得名于逻辑学家 Alfred Horn[6]。一个子句是文字的析取。
霍恩逻辑(Horn Logic)是一阶逻辑的子集。基于霍恩逻辑的知识库是一个霍恩规则的集合。

2.2.3 语义网络
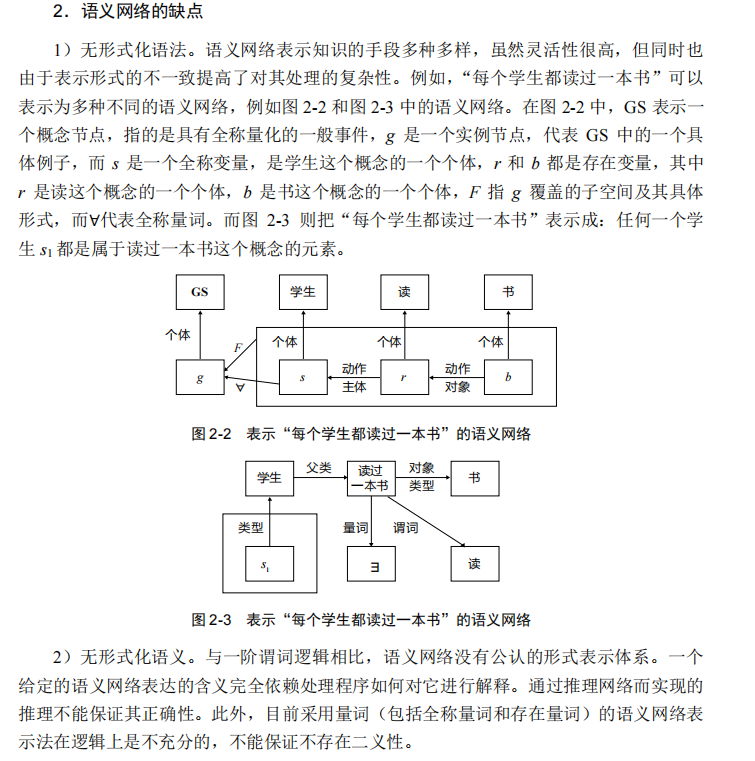
语义网络又称联想网络,它在形式上是一个带标识的有向图。
**图中“节点”**用以表示各种事物、概念、情况、状态等。每个节点可以带有若干属性。
节点与节点间的“连接弧”(称为联想弧)用以表示各种语义联系、动作。
语义网络的单元是三元组:(节点 1, 联想弧, 节点 2)。
例如(Tim Berners-Lee, 类型, 图灵奖得主)和(Tim Berners-Lee, 发明, 互联网)是三元组。
由于所有的节点均通过联想弧彼此相连,语义网络可以通过图上的操作进行知识推理。

2.2.4 框架
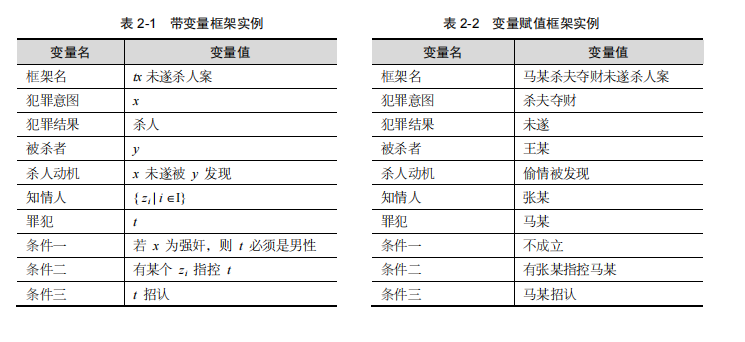
框架(Frame)最早由 Marvin Minsky 在 1975 年提出,目标是更好地理解视觉推理和自然语言处理。其理论的基本思想是:认为人们对现实世界中各种事物的认识都以一种类似于框架的结构存储在记忆中。当面临一个新事物时,就从记忆中找出一个合适的框架,并根据实际情况对其细节加以修改、补充,从而形成对当前事物的认识。

2.2.5 描述逻辑
描述逻辑可以被看成是利用一阶逻辑对语义网络和框架进行形式化后的产物。
描述逻辑一般支持一元谓词和二元谓词。**一元谓词称为类,二元谓词称为关系。**描述逻辑的重要特征是同时具有很强的表达能力和可判定性。描述逻辑近年来受到广泛关注,被选为 W3C 互联网本体语言(OWL)的理论基础。

2.3 互联网时代的语义网知识表示框架
着语义网的提出,知识表示迎来了新的契机和挑战,契机在于语义网为知识表示提供了一个很好的应用场景,挑战在于面向语义网的知识表示需要提供一套标准语言可以用来描述 Web 的各种信息。
早期 Web 的标准语言 HTML 和 XML 无法适应语义网对知识表示的要求,所以 W3C 提出了新的标准语言 RDF、RDFS 和 OWL。这两种语言的语法可以跟 XML 兼容。
2.3.1 RDF 和 RDFS
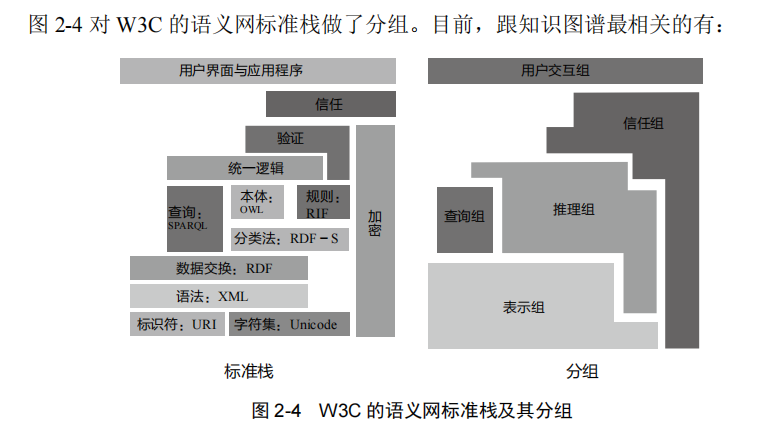
RDF 是 W3C 的 RDF 工作组制定的关于知识图谱的国际标准。RDF 是 W3C 一系列语义网标准的核心,如图 2-4 所示。
- 表示组(Representation)包括 URI/IRI、XML 和 RDF。前两者主要是为 RDF 提供语法基础。
- 推理组(Reasoning)包括 RDF-S、本体 OWL、规则 RIF 和统一逻辑。统一逻辑目前还没有定论。
- 信任组和用户互动组。
2006 年,人们开始用 RDF 发布和链接数据,从而生成知识图谱.

1.RDF 简介
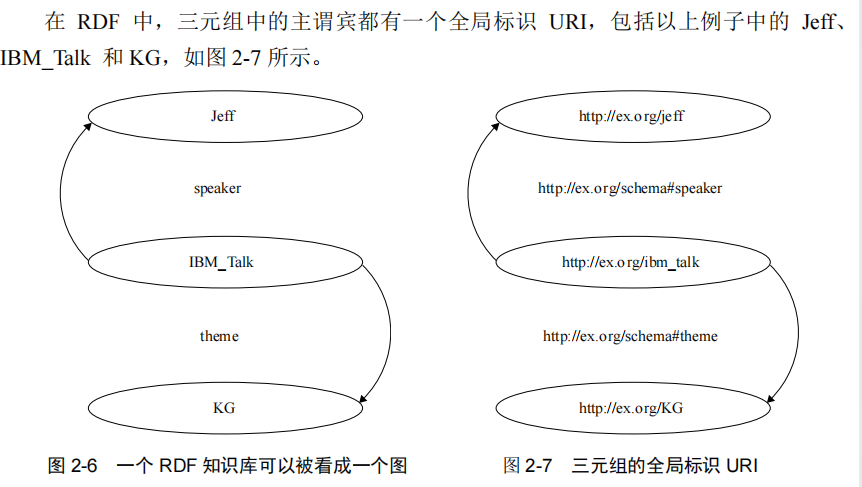
在 RDF 中,知识总是以三元组的形式出现。每一份知识可以被分解为如下形式:(subject, predicate, object)。
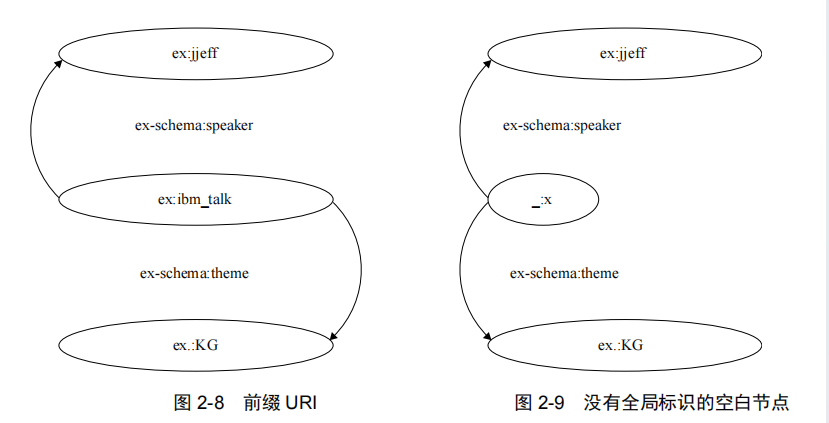
例如,“IBM 邀请 Jeff Pan 作为讲者,演讲主题是知识图谱”可以写成以下 RDF 三元组:(IBM-Talk,speaker,Jeff),(IBM-Talk,theme,KG)。
RDF 中的主语是一个个体(Individual),个体是类的实例。
RDF 中的谓语是一个属性。属性可以连接两个个体,或者连接一个个体和一个数据类型的实例。
换言之,RDF 中的宾语可以是一个个体,例如(IBM-Talk,speaker,Jeff)也可以是一个数据类型的实例,例如(IBMTalk,talkDate,“05-10-2012”^xsd:date)。
- 如果把三元组的主语和宾语看成图的节点,三元组的谓语看成边,那么一个 RDF 知识库则可以被看成一个图或一个知识图谱
-
全局标识 URI 可以被简化成前缀 URI。
-
RDF 允许没有全局标识的空白节点(Blank Node)。空白节点的前缀为“_”。
2.开放世界假设
不同于经典数据库采用封闭世界假设,RDF 采用的是开放世界假设。也就是说,RDF图谱里的知识有可能是不完备的,这符合 Web 的 开 放 性 特 点 和 要 求 。
TODO
2.5 知识图谱的向量表示方法
本节要描述的方法是把知识图谱中的实体和关系映射到低维连续的向量空间,而不是使用基于离散符号的表达方式。
2.5.1 知识图谱表示的挑战
在前面提到的一些知识图谱的表示方法中,其基础大多是以三元组的方法对知识进行组织。
知识以基于离散符号的方法进行表达,但这些符号并不能在计算机中表达相应语义层面的信息,也不能进行语义计算,对下游的一些应用并不友好。
在基于网络结构的知识图谱上进行相关应用时,因为图结构的特殊性,应用算法的使用与图算法有关,相关算法具有较高的复杂度,面对大规模的知识库很难扩展。
对于当前的数据量较大的知识图谱、变化各异的应用来说,需要改进传统的表示方法。
2.5.2 词的向量表示方法
1.独热编码
方法简单,但没有编码语义层面的信息,稀疏性非常强,当整个词典非常大时,编码出向量的维度也会很大。
2.词袋模型
词袋模型(Bag-of-Words,BoW)是一种对文本中词的表示方法。
类似于cnt数组
该方法将文本想象成一个装词的袋子,不考虑词之间的上下文关系,不关心词在袋子中存放的顺序,仅记录每个词在该文本(词袋)中出现的次数。
3.词向量
上面对词的表示方法并没有考虑语义层面的信息,为了更多地表示词与词之间的语义相似程度,提出词的分布式表示,也就是基于上下文的稠密向量表示法,通常称为词向量或词嵌入(Word Embedding)。产生词向量的手段主要有三种:
-
Count-based。基于计数的方法,简单说就是记录文本中词的出现次数。
-
Predictive。基于预测的方法,既可以通过上下文预测中心词,也可以通过中心词预测上下文。
-
Task-based。基于任务的,也就是通过任务驱动的方法。通过对词向量在具体任务上的表现效果对词向量进行学习
经典的开源工具 word2vec 中包含的 CBoW 和 Skip-gram 两个模型。
-
CBoW 也就是连续词袋模型(Continuous Bag-of-Words),和之前提到的 BoW 相似之处在于该模型也不用考虑词序的信息。其主要思想是,用上下文预测中心词,从而训练出的词向量包含了一定的上下文信息。整个模型在训练的过程就像是一个窗口在训练语料上进行滑动,所以被称为连续词袋模型。
-
Skip-gram 的思想与 CBoW 恰恰相反,其考虑用中心词来预测上下文词。
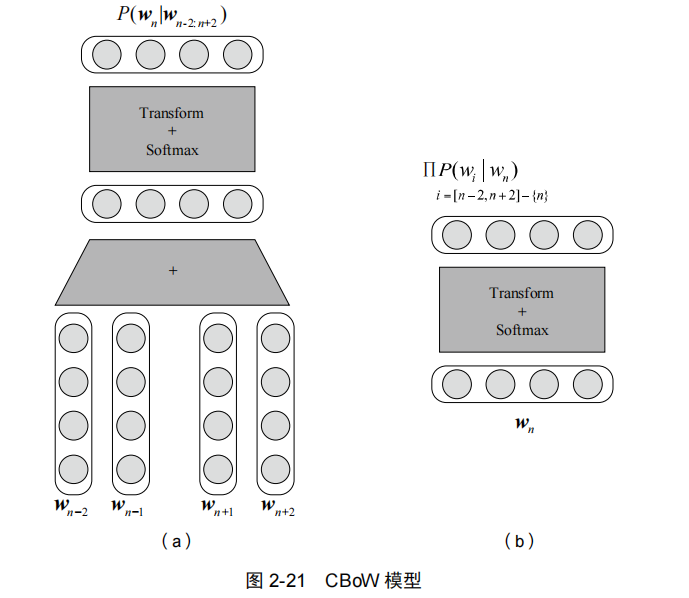
CBoW:如图 2-21(a)所示,其中 是中心词,,,, 为该中心词的上下文的词。将上下文词的独热表示与词向量矩阵 𝑬 相乘,提取相应的词向量并求和得到投影层,然后再经过一个 Softmax 层最终得到输出,输出的每一维表达的就是词表中每个词作为该上下文的中心词的概率。
Skip-gram:如图 2-21(b)所示,先通过中心词的独热表示从词向量矩阵中得到中心词的词向量得到投影层,然后经过一层Softmax 得到输出,输出的每一维中代表某个词作为输入中心词的上下文出现的概率。
在训练好的词向量中可以发现一些词的词向量在连续空间中的一些关系。
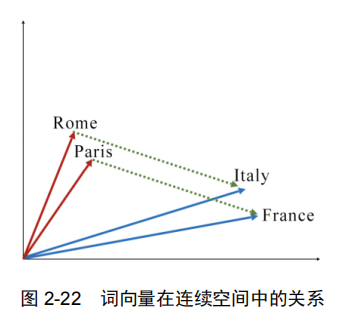
恰好可以简单地理解成知识图谱中的关系(relation)、(Rome, is-capital-of, Italy)和(Paris, is-capital-of, France),可以看作是知识图谱中的三元组(triple),这对知识图谱的向量表示产生了一定的启发。
2.5.3 知识图谱嵌入的概念
为了解决前面提到的知识图谱表示的挑战,在词向量的启发下,研究者考虑如何将知识图谱中的实体和关系映射到连续的向量空间,并包含一些语义层面的信息,可以使得在下游任务中更加方便地操作知识图谱。
把这种将知识图谱中包括实体和关系的内容映射到连续向量空间方法的研究领域称为知识图谱嵌入( Knowledge Graph Embedding )、 知 识 图 谱 的 向 量 表 示 、 知 识 图 谱 的 表 示 学 习(Representation Learning)、知识表示学习。
类似于词向量,知识图谱嵌入也是通过机器学习的方法对模型进行学习,与独热编码、词袋模型的最大区别在于,知识图谱嵌入方法的训练需要基于监督学习。
类似于词向量,经典的知识图谱嵌入模型 TransE 的设计思想就是,如果一个三元组(h, r, t)成立,那么它们需要符合 h+r ≈ t 关系,例如:

![[书生大模型]论文分类微调打榜赛二等奖-比赛方案分享](https://picbed.octalzhihao.top/img/myblog/cover/default_cover_15.webp)
![[Datawhale AI夏令营] 语音克隆比赛方案](https://picbed.octalzhihao.top/img/myblog/cover/default_cover_5.webp)

