
[书生大模型]论文分类微调打榜赛二等奖-比赛方案分享
比赛背景
该比赛算是“书生大模型实战营-第五期”的沐曦魔乐专场。

比赛任务就是在沐曦算力下微调InternLM-1.5B进行论文分类,由沐曦和魔乐社区提供赞助和平台支持,要求呢就是必须得用沐曦的算力来微调。
笔者最终比赛成绩为83.36,在比赛结束后特将比赛方案分享于此。

创建沐曦算力容器及配置环境
本任务使用D.run平台提供的沐曦算力完成,大部分时间白嫖了32G的,高峰期则使用了香港一区的64G。
https://console.d.run/zestu/market?regionId=sh-06
选择Pytorch镜像
安装 ms-swift
1 | conda create -n ms-swift python=3.10 -y |
中途服务器镜像更新过一次,最新版的镜像可能需要先
pip uninstall flash_attn再执行以下命令,不然会有版本问题。(PS:本文具有时效性,不确保该方案会适用于D.run未来更新后的镜像)
然后安装mx编译后的包
创建requirements.txt内容如下
1 | apex==0.1+metax2.32.0.3 |
1 | pip install -r requirements.txt -i https://repos.metax-tech.com/r/maca-pypi/simple --trusted-host repos.metax-tech.com --no-build-isolation |
安装提交魔乐平台的包
1 | pip install openmind_hub[all] |
构建数据集
考虑到公开的示例数据是十分类,并且只包括了26类中的6类,直接使用示例数据来进行训练上限肯定是有限的。(最早我试了,应该只能到四十几分数)
所以需要自己根据arXiv数据集造数据,我是直接把arXiv数据集下载到本地进行处理的。
先对数据集做一个简单的分析
1 | import json |
分析结果

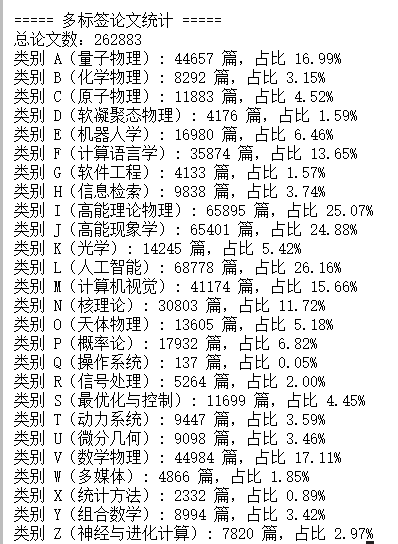
原本数据是不平衡的,并且有多类别的干扰,比较棘手。最开始我有尝试把多类别数据加进来,但去除同时包含这26类中的多类的,但后续感觉还不如直接用单类别的论文来的效果好。
抽取26类的子集
以下是从arXiv原始数据集中选择子集的脚本
这里放的是我最终采用的方法:直接舍弃了多类别数据,只看单一类别的论文。
1 | import argparse |
使用了两种模式,custom为自定义每一类的数量,uniform为统一数量生成。主要原因是最开始我发现,部分数据使用官方公开的示例数据效果似乎可以有一点点提升,所以为了数据类别的平衡性就选择自定义数量生成之后和示例数据做一个合并。
但后面随着训练数据量的变大就懒得采用这种方法了,直接选择了统一数量随机生成。
构建预训练与sft数据
先有抽取脚本抽取出jsonl格式的子集,然后作为输入文件运行以下脚本
创建一个make_pretrain.py脚本如下:
1 | #!/usr/bin/env python3 |
make_sft.py脚本如下(修改提示词直接在此脚本进行):
1 | #!/usr/bin/env python3 |
构建验证集(给OpenCompass的评测数据)
使用以下脚本根据原始数据集提取出的子集jsonl生成一个可用于OpenCompass单选题评测的csv。
1 | import json |
在编写一个配置脚本,设置好模型路径、数据集路径和训练参数,用OpenCompass测评即可。
1 | from mmengine.config import read_base |
高峰期的B榜测评往往要数小时,所以本地有个评测的验证集还是挺有用的。(我大概用了2w+的数据构建了一个验证集)
很巧的是在我自己的验证集上表现最好的也是我最终有效最高分对应的模型,跑了86.12。

预训练
参考baseline文档来编写的训练脚本如下
1 |
|
训练完 swift export 合并一下权重就ok了。
1 | swfit export --adpters /path/to/your/model/ --merge_lora true |
SFT 指令微调
1 |
|
训练了多个模型后,总结出的经验:对于1.8B模型训练不同规模的数据,第一轮sft训练基本都是2~4个epoch为最佳,再继续训练的准确率反而更可能下降。如果此前pretrain的轮次多,sft的轮次似乎也可以略高一点,但也不能过高。(在隔壁赛道试验发现,8B模型的最佳训练轮次似乎是要更多一些)
最开始我是使用了1k左右的数据复现以上的baseline,其实评测结果已经达到了60分左右。
我又扩大数据量到3k左右(平均采样),其实就妥妥达到70分了。所以我觉得只要跟着教程耐心复现,拿个三等奖是难度不大的。
baseline基础上继续优化的思路
由于隔壁10分类赛道可以使用A100算力,更便于我不断去训练尝试。所以我是先把10分类的赛道分数刷到还算看得过去再来做本赛道的。而对10分类来说,我当时测出来似乎并非数据量越大越好,所以一开始就没想着扩大数据量。
所以在开始做26类的任务时,我最初是把数据量的数量级稳定在3k,然后从优化数据质量入手。
过程中尝试了许多方法,这里先列举几个试验过程(但非产生最优模型的主要因素):
- 重写sft的system prompt:例如把中文改成英文,运用提示词工程的常见手段丰富内容等。最终效果却都不理想,改成英文后甚至会有明显的成绩下滑。得出的结论是:还是用一句简洁明练的中文提示词最为有效。
- 在平衡类别的基础上再平衡发表年份,以采集更多样化的论文风格:也提升极小,聊胜于无,后续就没这么折腾了。
- 使用更多的提问模版(直接让GPT写):新增了4个模板,增加数据的多样性。喜报是成绩有明显提升了,不过现在回想起来也可能是数据量变大所带来的长进。
- ReSFT:训完一个模型后用OpenCompass在验证集做一次测评,再用回答错的论文信息对模型进行2次训练。此方法刷榜时还是挺有用的,当模型达到一个还不错的分数且和前面选手相差不大的时候,这样多次训练一下往往还是可以让成绩再提0.0x甚至0.x的。
前2/3以上的赛程中,其实我都在用3k左右的数据量+各种优化尝试训了一些模型结果。但此时的最好结果就只有80点几,大部分提交都在75~80分。
到后期大家开始冲榜,卷起来的时候,这个分已经不够看了,以每天十几名的速度不断往下掉。
后面病急乱投医,我用1w+的数据试了一下,结果突然就有了明显优化。本地OpenCompass评测验证集的结果更是一下子提了5个点。
最后又用2w+的数据跑了一次(当时觉得已经够多了,毕竟OS类就一千篇左右,再多好像就没法让类别分布平衡了),跑完用上述说的“ReSFT”又优化了零点几,就成了最终83.36的结果。
后续由于时间原因也没有再试更多数据了,压线拿了个60名还是非常幸运的!😁
感悟:在微调数据质量有保障的情况下,扩大数据量终归是硬道理😂
![[书生大模型]论文分类微调打榜赛二等奖-比赛方案分享](https://picbed.octalzhihao.top/img/myblog/cover/default_cover_15.webp)
![[Datawhale AI夏令营] 语音克隆比赛方案](https://picbed.octalzhihao.top/img/myblog/cover/default_cover_5.webp)

